Leading GenAI Evaluation Platform
Validate GenAI quality with comprehensive testing tools designed for AI developers and enterprises.

Enable AI Adoption by Measuring GenAI Performance
Track, measure, and optimize your AI systems with comprehensive performance metrics and evaluation criteria.
Measure Agent/Bot Output
Compare performance against human expected outcomes and competing AI solutions.
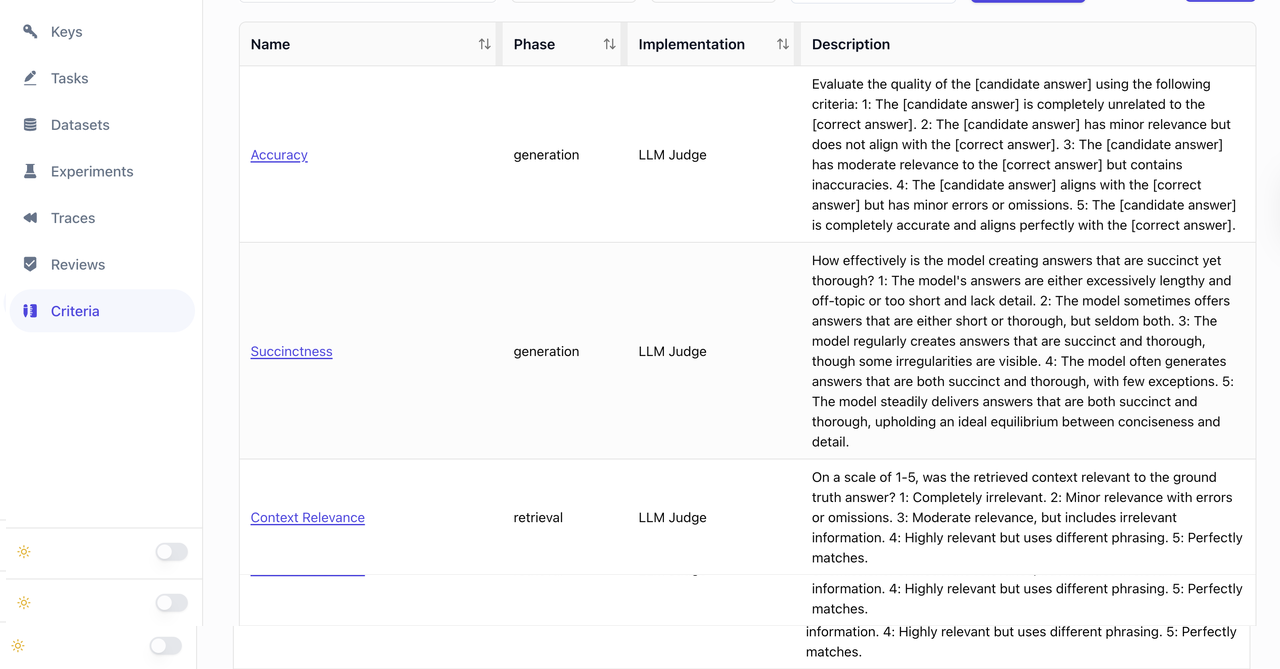
Establish key benchmarks
Automatically process industry standards.
Establish objective evaluation criteria
Incorporate insights from employees/customers and industry insights.
Comparative analysis
Ragmetrics compares the outputs from different AI models, system prompts, and databases that allow AI developers to make wise decisions.
Easy to configure and integrate
The RagMetrics platform provides real-time scoring on performance, grounding accuracy, and relevance. This ensures AI systems are optimized for reliability and domain-specific outputs. Accelerate deployments and master AI innovation with confidence and simplicity.
Deploy anywhere - Cloud, SaaS, On-Premises
Choose the implementation model that best fits your needs: cloud, SaaS, or on-premises. Stand-alone GUI or API model.
Cloud
Fast, flexible deployment with zero infrastructure overhead. Ideal for scaling quickly.
SaaS
Fully managed service with continuous updates and maintenance. Get started instantly.
On-Premises
Deploy securely within your own environment. Full control and compliance.
GUI or API
Use our UI or integrate directly into your existing tech stack with REST APIs
Frequently Asked Questions
Can RagMetrics compare LLMs like Claude and GPT-4?
Yes. RagMetrics was built for benchmarking large language models. You can run identical tasks across multiple LLMs, compare their outputs side by side, and score them for reasoning quality, hallucination risk, citation reliability, and output robustness.
Does RagMetrics support an API for LLM evaluation?
Yes. RagMetrics provides a powerful API for programmatically scoring and comparing LLM outputs. Use it to integrate hallucination detection, prompt testing, and model benchmarking directly into your GenAI pipeline.
Can I run RagMetrics in a private cloud or on-premises?
RagMetrics can be deployed in multiple ways, including as a fully managed SaaS solution, inside your private cloud environment (like AWS, Azure, or GCP), or on-premises for organizations that require maximum control and compliance.
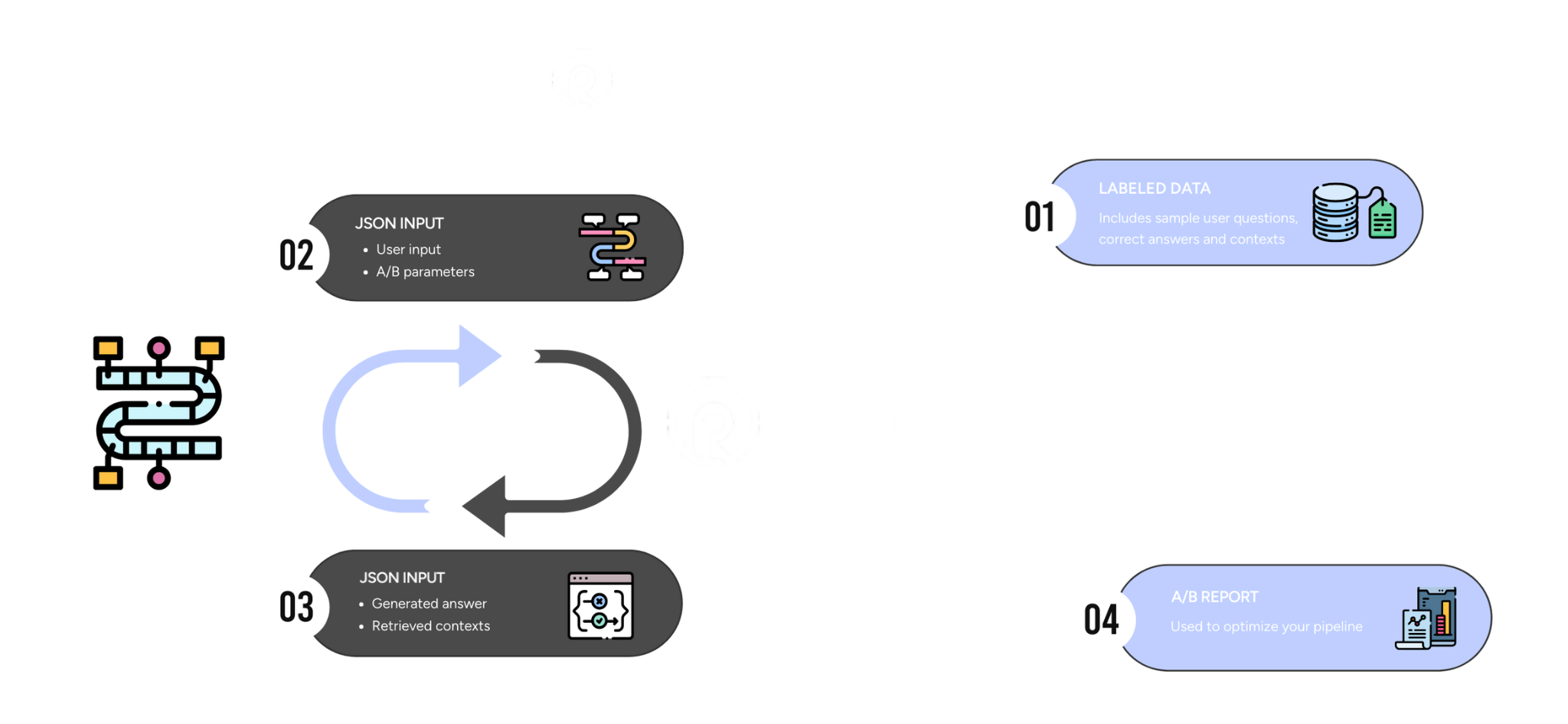
How do I run a GenAI evaluation experiment with RagMetrics?
Running an experiment is simple. You connect your LLM or retrieval-augmented generation (RAG) pipeline, define the task, upload a labeled dataset or test prompts, select your scoring criteria like hallucination rate or retrieval accuracy, and then run the experiment through the dashboard or API.
Can I evaluate my own proprietary or open-source model with RagMetrics?
RagMetrics is model-agnostic and supports any public, private, or open-source LLM. You can evaluate outputs from models like Mistral, Llama 3, or DeepSeek, and compare results to popular models like GPT-4, Claude, and Gemini using the same scoring framework.
See RagMetrics in action
Request more information or request a demo of the industry's leading LLM evaluation platform for LLM accuracy, observability, and real-time monitoring.