
Why AI Evaluations Matters
Hallucinations erode trust in AI
65% of business leaders say hallucinations undermine trust.
Manual evaluation process doesn't scale
Automated review cuts QA costs by up to 98%.
Enterprises need proof before deploying GenAI agents
Over 45% of companies are stuck in pilot mode, waiting on validation.
Product teams need rapid iteration
Only 6% of lagging companies ship new AI features under 3 months.
Purpose-Built Platform for AI Evaluations
AI-Assisted Testing
Automated testing and scoring of LLM and agent outputs
Live AI Evaluations
Evaluate GenAI output in near real time
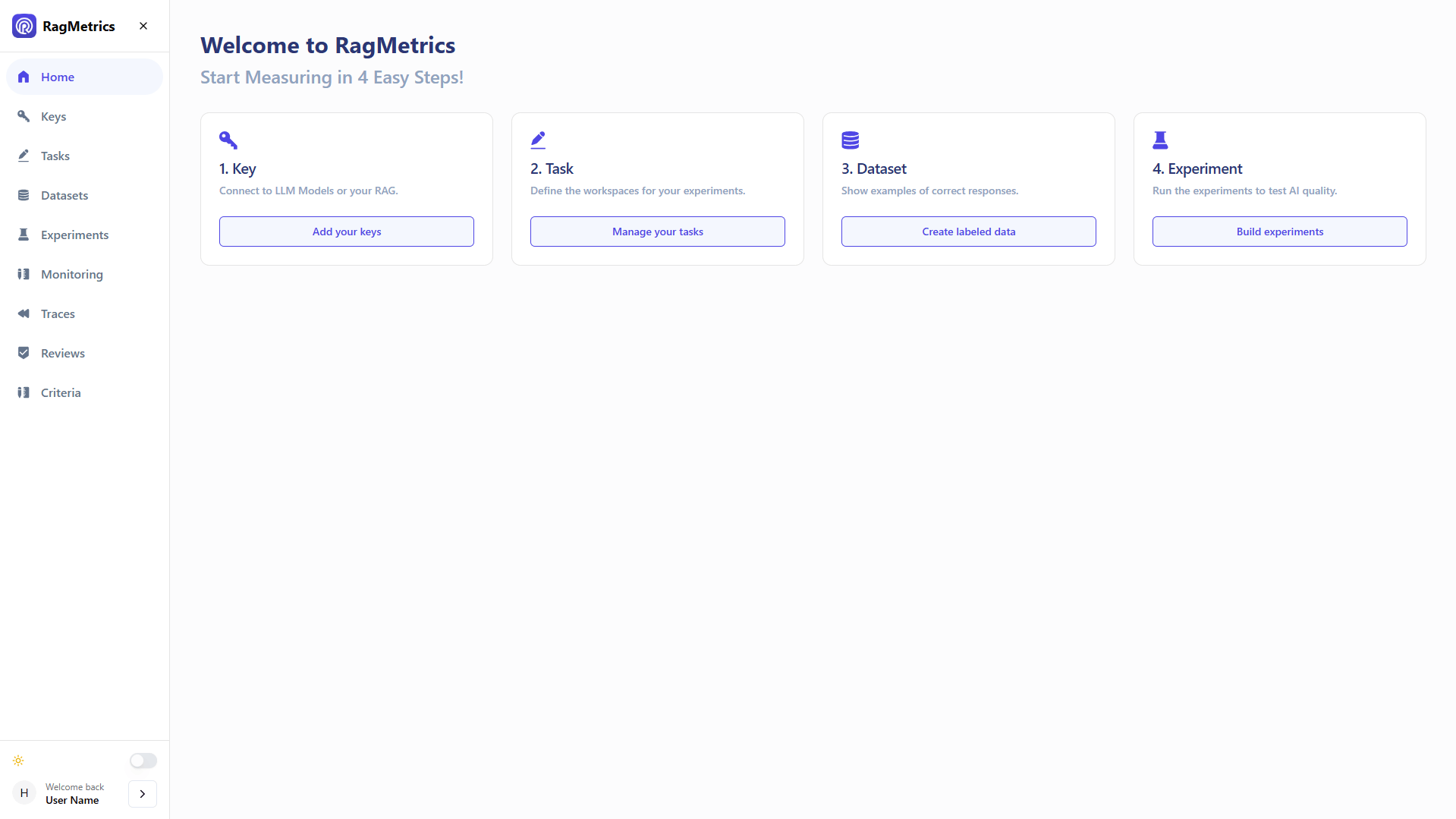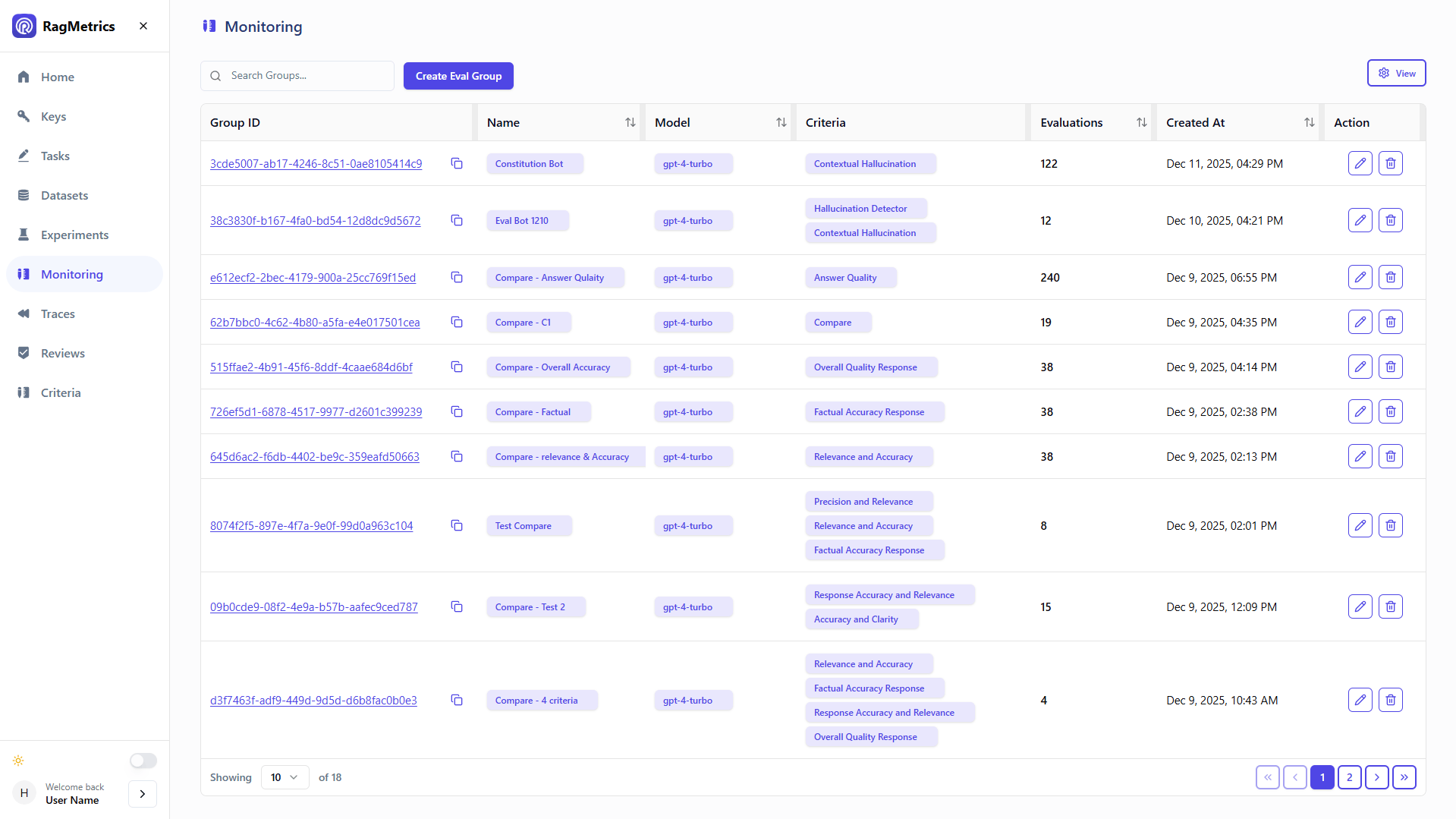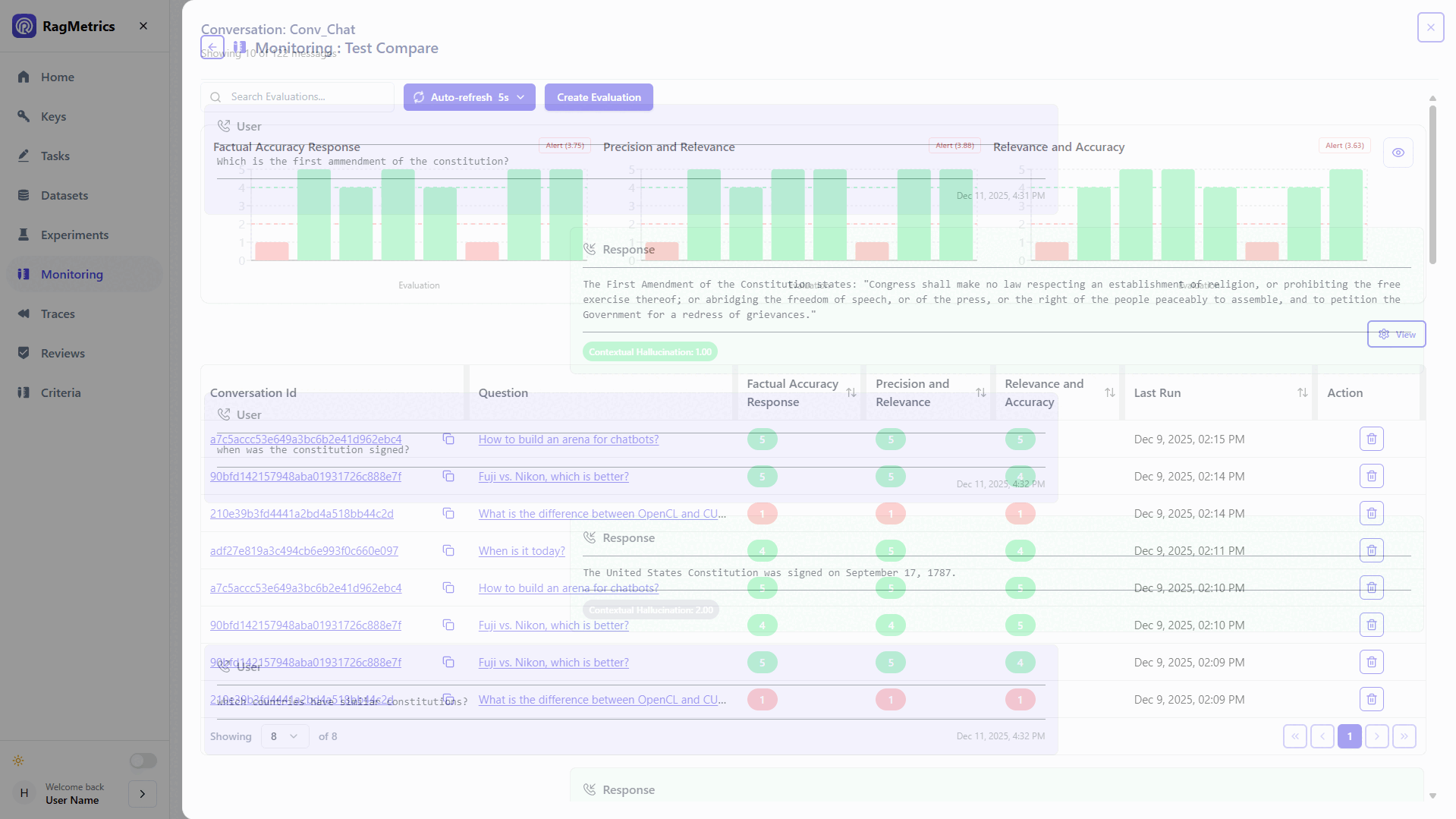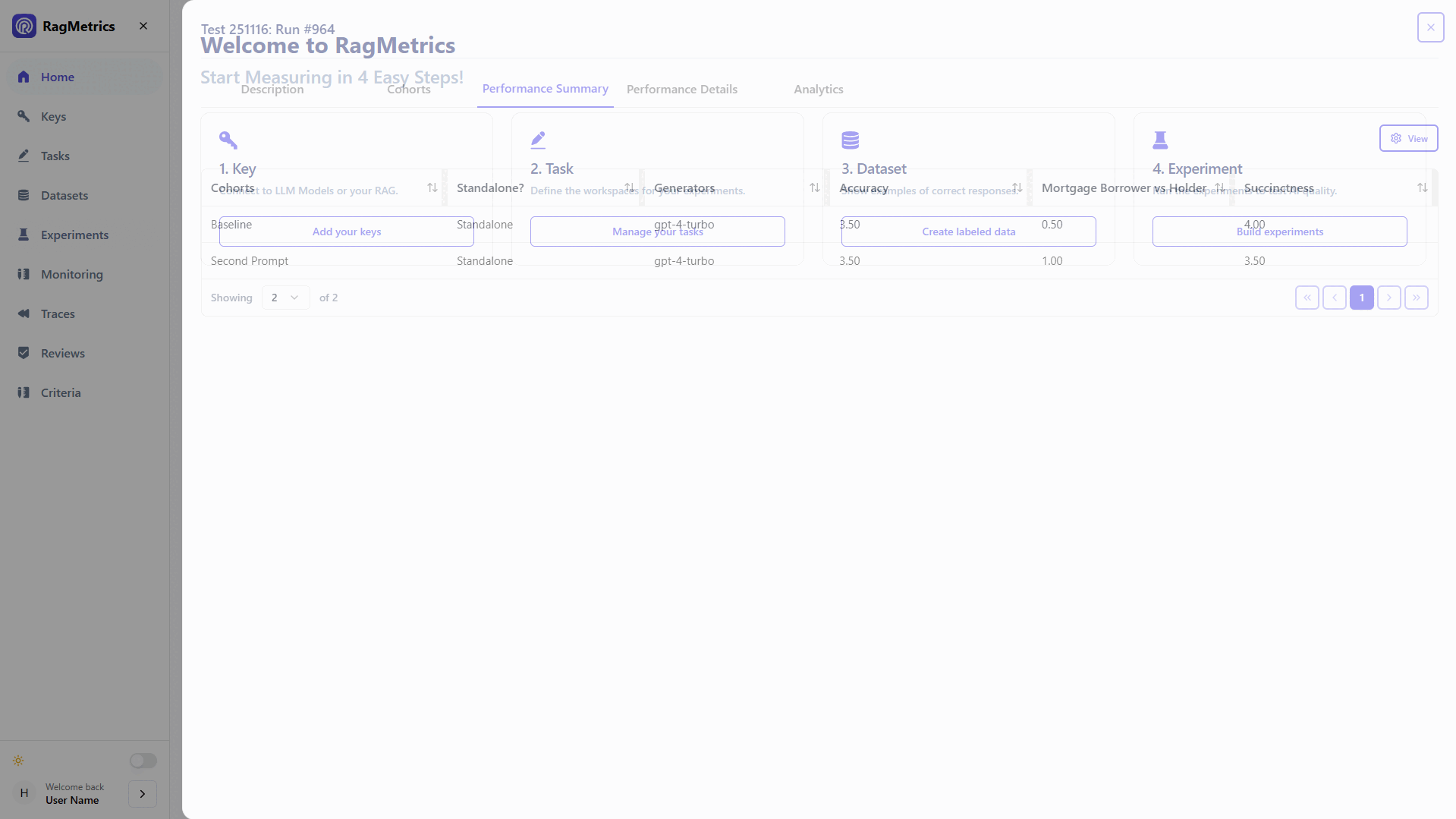
Hallucination Detection
Automated detection of AI-generated inaccuracies
Performance Analytics
Real-time insights and performance monitoring

Flexible and Reliable
LLM Foundational Model Integrations
Integrates with all commercial LLM Foundational models, or it can be configured to work with your own.
200+ Testing Criteria and Create your own Criteria
With over preconfigured criteria and flexibility to configure your own, you can measure what is relevant for you and your system.
AI Agentic Monitoring
Monitor and trace the behaviors of your agents. Detect if they start to hallucinate or drift from their mandate.
Deployment Cloud, SaaS, On-Prem
Choose the implementation model that fits your needs -- cloud, SaaS, on-prem. Stand Alone GUI or API model.
AI Agent Evaluation and Monitoring
Analyze each interaction to provide detailed ratings and monitor compliance and risk
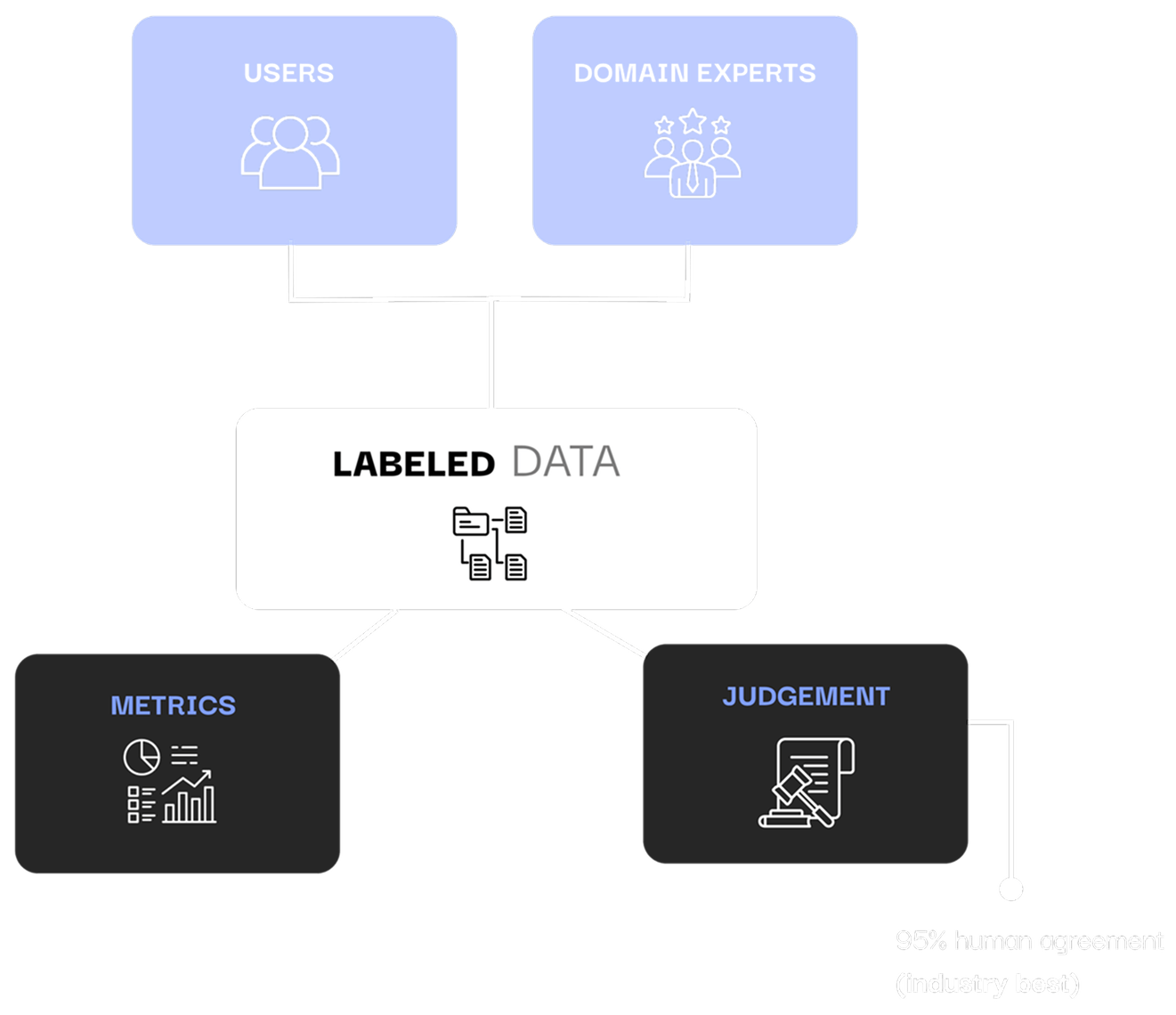

Leading teams trust RagMetrics to validate and improve their GenAI outputs.
What Our Customers Say
"I was thrilled to see this graph from the RagMetrics Team, yesterday. It demonstrates that our RAG methodology at Tellen employing techniques from semantic search to LLM-based summarization significantly outperforms GPT-4 and all other large language models. Excited to boost these numbers by both leveraging more sophisticated RAG—HyDE, reranking, etc. and other language models, for which we're already building private endpoints in Microsoft Azure. Seems Llama3 could be a good bet!"

Girish Gupta
Tellen
"I have had the pleasure to work with RagMetrics Team. They are very knowledgeable on the areas of AI, LLM, as well as business. They know that a successful product is more than just technology. The results provided by RagMetrics are helpful for any AI product development and the company is very open to feedback and customizations. I would recommend anyone with an AI application to look into what RagMetrics can do for their use case."

Lawrence Ibarria
AI Product Leader
Frequently Asked Questions
Validate LLM Responses and Accelerate Deployment
RagMetrics enables GenAI teams to validate agent responses, detect hallucinations, and speed up deployment through AI-powered QA and human-in-the-loop review.
Get Started